
Computer Vision. For most of human history, sight was something only living beings could possess. Eyes captured light. Brains interpreted it. Machines, no matter how powerful, were blind.
A camera could record.
A sensor could measure.
A computer could store.
But none of them could understand what they were seeing.
Today, that has changed.
Your phone unlocks when it sees your face. Cars detect pedestrians. Hospitals scan X-rays using AI. Satellites track deforestation in real time. Security systems recognize suspicious behavior. Shopping apps identify products from photos.
All of this is powered by one field: computer vision.
Computer vision is the branch of artificial intelligence that teaches machines how to “see.” Not just capture images, but interpret them. Not just record pixels, but understand meaning.
This blog explains how computers learn to see, what actually happens inside these systems, and why computer vision is reshaping nearly every industry on Earth.
From Pixels to Perception
A digital image is nothing more than a grid of numbers. Each pixel contains values for color and brightness. To a computer, a photograph of a dog and a photograph of a chair are just arrays of values.
Humans, however, instantly recognize shapes, edges, depth, and meaning. We don’t see pixels. We see objects, faces, emotions, and intent.
The challenge of computer vision is bridging that gap.
Early attempts relied on hard-coded rules. Engineers wrote instructions such as:
- “If a region has two dark circles above a line, it might be a face.”
- “If edges form a rectangle, it might be a door.”
These systems worked only in controlled environments. A slight change in lighting, angle, or background broke them. Real-world vision is far too complex for fixed rules.
The breakthrough came when machines stopped following rules and started learning.

Teaching Machines to See
Modern computer vision systems are built using deep learning. Instead of telling the computer what a face looks like, engineers show it millions of faces.
The training process works like this:
The system is given an image.
It makes a guess: “This is a cat.”
It is told whether it is right or wrong.
The error is calculated.
Internal parameters are adjusted.
The process repeats.
Over time, the model learns what patterns tend to appear in cats, cars, trees, lungs, roads, or tumors. It does not memorize images. It learns relationships between shapes, textures, edges, and colors.
What emerges is not a rulebook, but a highly complex mathematical structure that can recognize patterns in new images it has never seen before.
The machine never “sees” a cat the way you do. It detects arrangements of visual features that statistically match what it learned about cats.
To you, it feels like recognition.
To the system, it is probability.
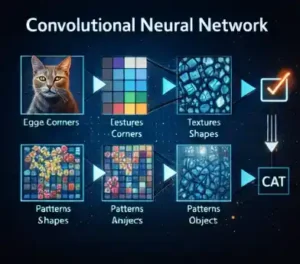
Convolutional Neural Networks: The Visual Brain of AI
At the heart of computer vision is a structure called a convolutional neural network, or CNN.
A CNN processes images layer by layer.
The first layers detect very simple features:
- edges
- corners
- light and dark regions
The next layers combine these into shapes:
- curves
- textures
- contours
Deeper layers combine those into parts:
- eyes
- wheels
- leaves
And the final layers recognize full objects:
- faces
- vehicles
- animals
- organs
This hierarchy mirrors how the human visual cortex works. The model does not jump directly from pixels to meaning. It builds understanding step by step.
That layered perception is what allows machines to recognize objects in messy, real-world scenes.
Why Vision Is Harder Than It Looks
To humans, vision feels effortless. But it is one of the hardest problems in computing.
Consider what a vision system must handle:
- lighting changes
- shadows
- occlusion
- motion blur
- angle variation
- background noise
- partial visibility
- scale differences
A cat in sunlight looks very different from a cat at night. A car seen from the front looks nothing like one seen from above. A face with glasses is not the same as a face without them.
Humans adapt instantly. Machines must learn these variations from data.
That is why modern computer vision systems require massive datasets. They need to see millions of examples across conditions to generalize.
The more diverse the data, the better the vision.
From Recognition to Understanding
Early computer vision focused on classification: “What is in this image?”
Today, systems go much further.
They can:
- locate objects within images
- track movement across video
- estimate depth and distance
- detect emotions on faces
- read handwriting
- identify diseases in scans
- reconstruct 3D environments
A self-driving car does not just recognize a pedestrian. It predicts motion. It estimates speed. It understands traffic rules. It anticipates danger.
A medical imaging system does not just see a tumor. It measures growth. It compares scans over time. It supports diagnosis.
Vision is no longer passive. It has become perceptive.

Why Computer Vision Is Transforming the World
Vision connects AI to the physical world.
Language models work in text.
Vision models work in reality.
They allow machines to interact with:
- roads
- factories
- farms
- hospitals
- cities
- oceans
- forests
That is why computer vision drives:
- autonomous vehicles
- smart agriculture
- medical diagnostics
- retail automation
- security systems
- robotics
- satellite monitoring
Wherever there is a camera, there is potential intelligence.
Machines can now observe the world continuously, at scale, without fatigue.
This is not just automation.
It is perception at machine speed.
The Limits of Machine Vision
Despite its power, computer vision is not human sight.
It lacks:
- common sense
- context awareness
- emotional understanding
- lived experience
A model may identify a person holding a knife. It does not know if that person is a chef, a surgeon, or a threat. It sees patterns, not intent.
Vision systems can also fail in surprising ways:
- unusual lighting
- rare objects
- cultural differences
- biased training data
That is why human oversight remains essential.
Vision AI is powerful, but it is not wise.

Final Thought
For thousands of years, sight belonged only to living beings.
Now, machines see.
Not with eyes.
With mathematics.
With patterns.
With probability.
Computer vision does not experience the world. It models it.
But as these models grow more capable, they begin to bridge the gap between digital intelligence and physical reality.
We are entering an era where machines no longer just compute.
They perceive.
And once a machine can see, the world becomes its interface.
See more >>> Zara AI breakthrough